How to download all xkcd comic!
- 22-10-2017
- python

Share:
Copy
If you never heard of xkcd comics! don't worry you are not alone. xkcd is an awesome website and has thousands of comic related to Sarcasm, Math adn Computer.
When you visit the website you can see random comic! by clicking on the random button or browse them all one by one.
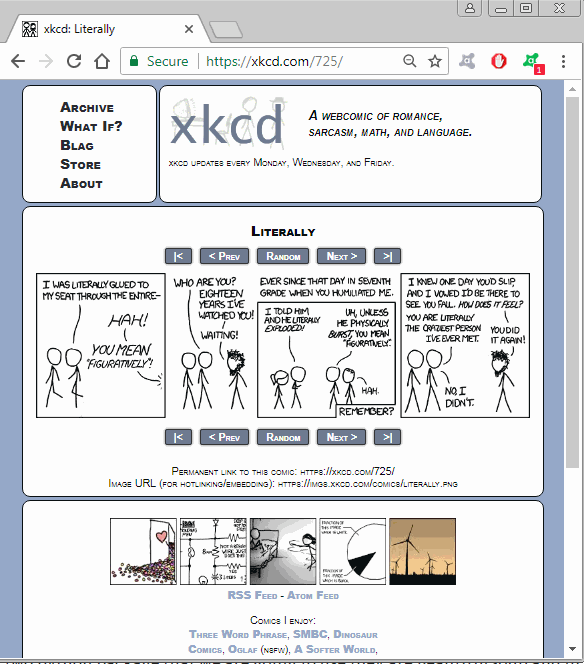
The basic url of the site looks like this https://xkcd.com/i/ where i is the id of comic, which starts from 1 and goes up to 1900+ so if you browse http://xkcd.com/149/ you will find a comic there.

The first thing we are going to do is inspect the web page source containing the image in a browser, just right click on the image and select inspect. It will show us this screen!
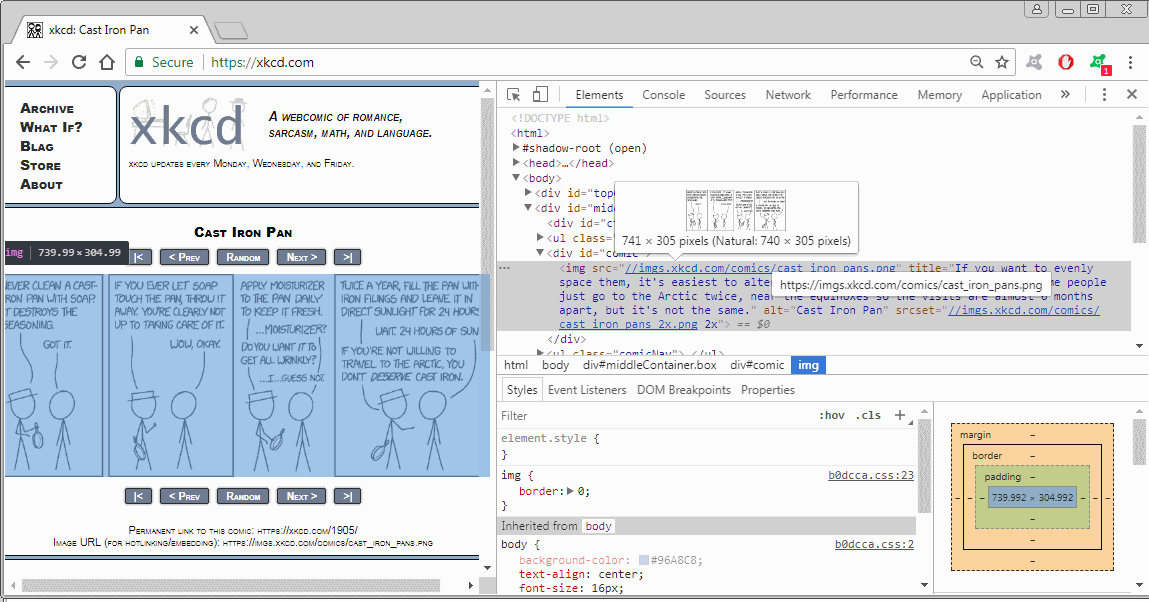
Here we can see under the img tag the location of the image in the xkcd server. Now you can just download the image by clicking on the link. The nice thing about xkcd is that they have different names for all the comic you can see this one has cast_iron_pans.png as the image name.
Now what we need is a program that will connect to all the links from i=1 to i=1900 and while doing so extract the image link under the img tag and download it with the same name it has.
So we just need to write a script that will do the hard job for us. Its takes only 15 lines of python code with the urllib module and BeautifulSoup library.
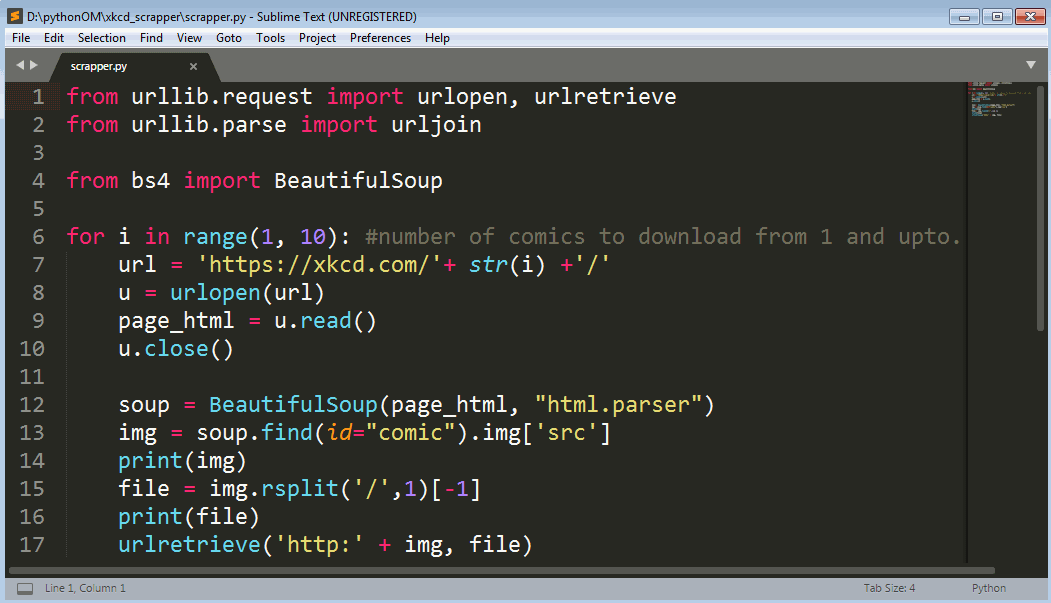
The code works in the following ways.
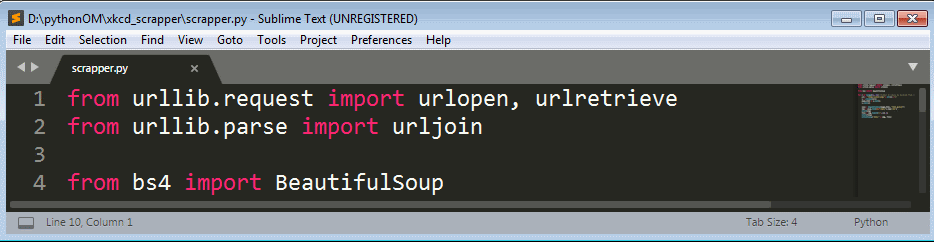
line-1 to 4: imports the urlopen, urlretrieve and urljoin methods from the urllib module also imports BeautifulSoup from bs4 library. You can read more about BeautifulSoup here and about urllib library here.
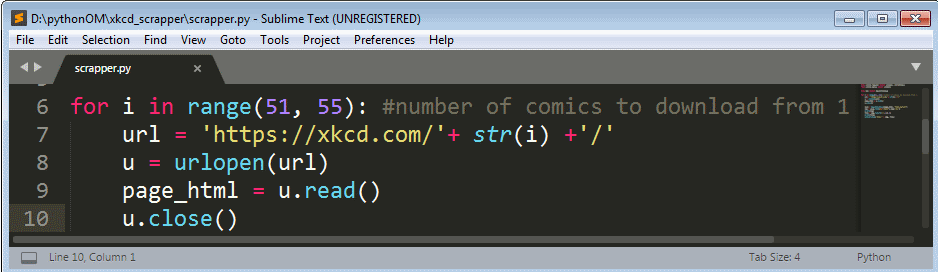
line-6: This is the begnning of our for loop which contains all the necessary steps to navigate to different page and download each comic image on that page. Here we set the range from 1 to 10. If we setthe range( ) function like this range(10) the it will start from 0 which we dont want. So basically what are we going to do is repeat all the steps or codes inside the for loop block 9 times, yes! 9 times as python range( ) function counts till n-1 in our case 10-1.
line-7: Here we declader a variable url which will hold the page url we need to visit. It has two part one is fixed and the other is the id which changes with each loop.
line-8: Here we call the urlopen method that we imported in the beginning and pass our url variable as the attribute to the urlopen method. What this is going to do is that it will make a connection to the url and make an object containing all the page information.
line-9: Here we make a variable page_html which will hold the entire raw html of the web page, which we collect by using the read( ) function.
line-10: Here we just closed the connection because we got all the information we needed.
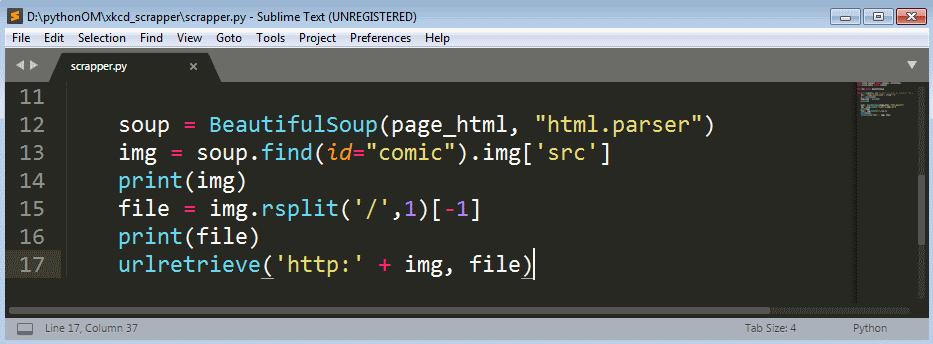
line-12: Here we called the BeautifulSoup method and passed two attributes one is the raw html of the web page we want to crawl and the other is the parser we want to use, we choosed the html.parser which does the job well.
line-13: Here we clled the BeautifulSoup find method and passed the attribute id="comic" which we want to find. Because the image we want to download is in the div tag with id comic. Again by adding img['src'] we crawled inside the div tag to find the img tag and pulled out the src of the img tag and hold it in the variable img.
line-14: Here we just printed the img variable which holds the address of the image.
line-15: Now we are all set to download the file so we created a file extension and name of the image so that we can just pass it to the urlretrieve method to download the image. Here we just used the url variable which holds the full address of the image, so we just used the rsplit function to cut the last portion of the link after this '/' so we get the name with extension of the image.
line-17: Here we called the urlretrieve method and passed the details to download the image. The first being the full link to the image and the second is the file name with extension. We added the string 'http:' because the img variable doesn't have it.
Now it will start downloading the images and will store it in the same directory in which we stored the script file. Here is a snapshot of what it is going to look!
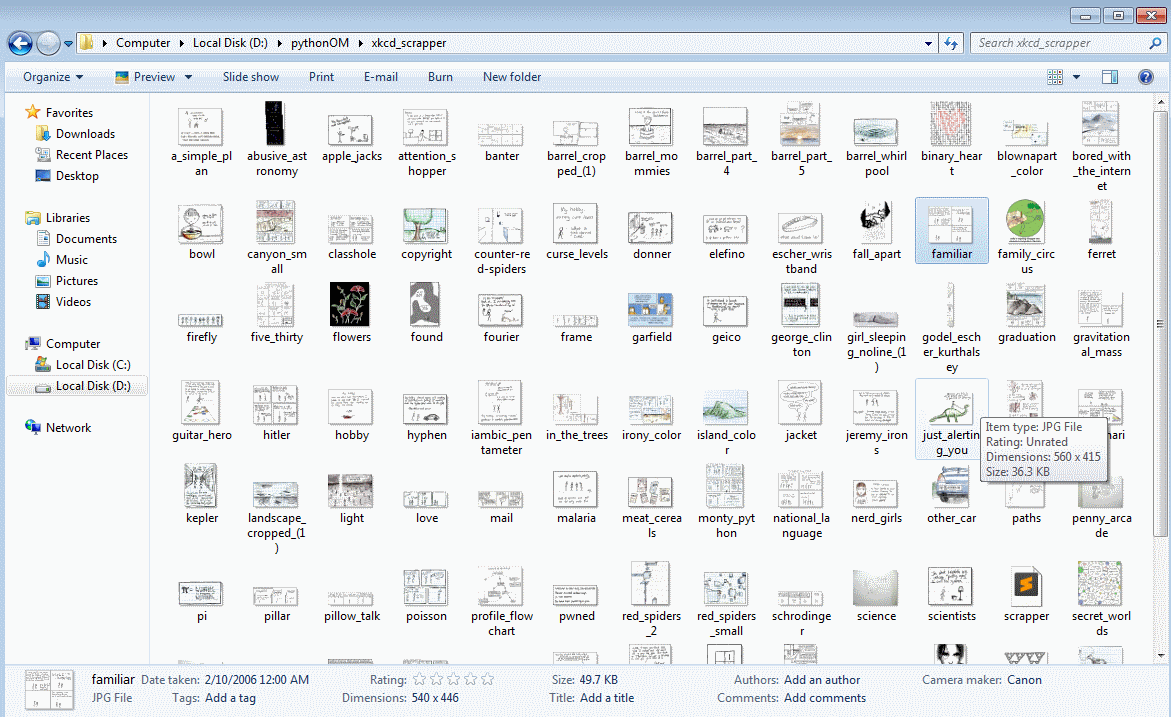
This is an awesome! example how effective web scraping can be when we need to find specific information from a site and make our life easier. In the same way we can do some awesome stuffs on the internet we just need to open our mind and look out to the vast opportunity out there.