Using Python and BeautifulSoup to Download all Avengers Character images.
- 20-04-2018
- python

Share:
Copy
Python and BeautifulSoup are the ultimate tool to make the life of a programmer easy. When there is a task involving repetation of steps that can be broken down to few lines of instructions, then its always good to write a python script to do the task.
I needed images of all the Avengers Characters for my small PHP project here. So surfing on the web I found the website which has listed all the Avengers character images along with their names. But the list was long so to download all the images along with the names of the characters I came up with a python script which does the job. Here lets proceed step by step:
Step 1:
The first step is to study the website and find out the way in which everything is organized. We start by inspecting the first image and try to understand how the HTML is organized.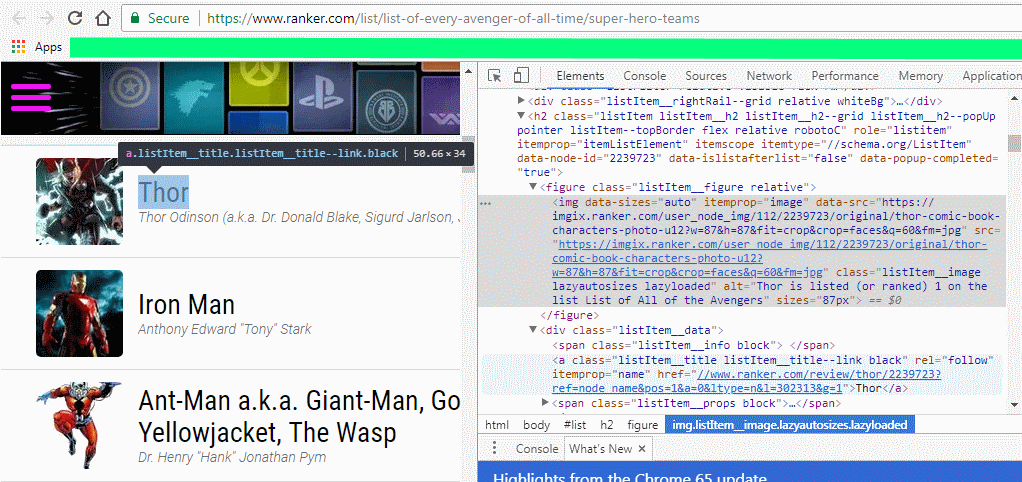
It can be clearly seen that all the names of the character are under the a tag In the first case its Thor. Further only the characters images are under the img tag and has identifier itemprop: image so we can use this to scrape all the images. Also all the names can be extracted by using the class: listItem__title listItem__title--link black as identifier.
Step 2:
Now that we have analyzed the website and noted all the important result, we are ready to write our script. The python script is similar to what i used for downloading all xkcd comic images here. because most of the code are same and also entire code is explained line by line so you may want to take a look there too.Now lets write our script which will download all Avengers character images along with the character name. Here is the preview from line 1-8:

From line 1-5 we just imported all the parameters we are going to use later in the script. On line 7 we started our try and except clause. So whenever an error occurs we can break and jump to our except clause and print what went wrong. Next on line 8 The variable url is made containing the exact link to the page from which we are going to download the images.
Now lets look at the preview from line 10-16:

Here on line 10 we build our headers dictionary which will hold our headers. Headers are the first information about the user which the server checks before making the connection. On line 11 we defined the key User-Agent to the dictionary headers and assighed the value which is the actual header we are going to use.
Here on line 12 the begining is made to establish the connection. The firts is the variable req which uses the urllib.request method to construct the request by using the headers and the url we provided. Next on line 13 variable resp uses the urllib.request.urlopen() method to make a connection and gather the web page. Next we just print connection ok just to know that all went well. The variable respData holds the entire web page by using the method .read() in the end we just close the connection using the method .close() as we have the entire web page on the variable respData.
Step 3:
Now the remaining part the most important part of our script lets take a look: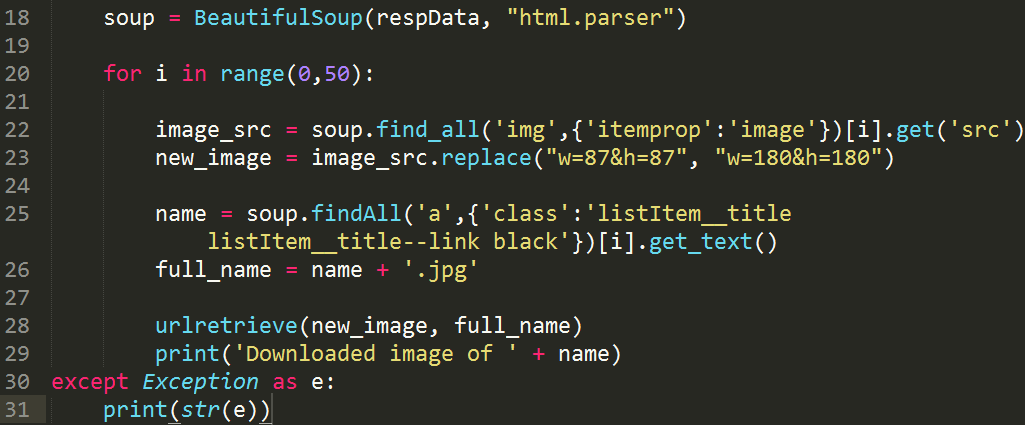
We first build our object soup which uses BeautifulSoup to process our respData with the help of html.parser Now the main part of the script is the for loop which will download images one by one. To better understant the loop lets break it down further.
line 22
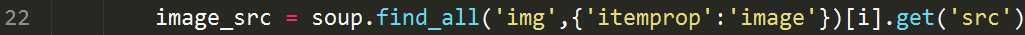
We know that all the images in the page which has identifier itemprop: image are the images which we want to download so we can use the BeautifulSoup find_all() method to find all the img tag on the page which has identifier itemprop:image . Also we dont want the entire contents of img tag but we just want the contents under src so we use the method .get('src') along with the index i of the loop which specifies to only grab the ith img. This is because the find_all() method will list all the img tag so we count from 0 which specifies to grab the first img tag and the 1 which specifies to grab the second and so on.
line 23

If you see the src image link you can see the values of w and h which represents the width and height of the image. By default they are set to 87 and 87 on the page but for our purpose we needed slightly bigger image so we have to modify the src link of the image we gathered above. To do this here we just used the python replace() function to find the old w=87&h=87 and replace it with the new w=180&h=180it is then stored in the variable new_image.
line 25

So now we are done with the image link its time to focus on the character name. Well we can slice or cut from the image link but the page also has the name along with the character image. So we again use the BeautifulSoup .findAll method to find all the a tags in which class:listItem__title listItemtitle--link black is present and again use the loop index to grab the first then second and so on and use the .get_textmethod to extract the text from the a tag which is the character name. line 26 Next we just added the .jpg at the end of the character name and hold it inside the variable full_name.
line 28

Now as we have both the image link as well as the name along with its format we are ready to download the image. We use the urlretrive function to download the image by providing it the new_image which is the full image link and full_name which is the name of the character along with its format in which we want to store it. Finally we just print out the ongoing result. As all the code are in the loop so it will be repeated for 50 times and in each repetation one image is downloaded.
In the end there is the exception clause which will print the reason when an error occures in our try clause. Finally we run the script and all seems to work properly. ;-)
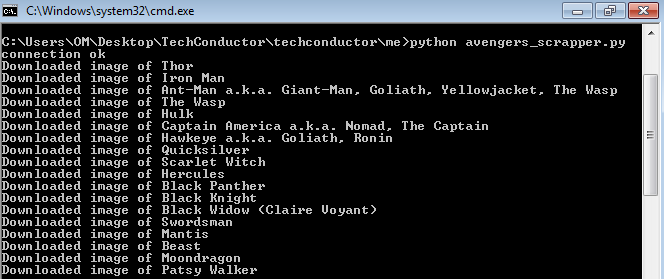
Here is another snapshot of the folder containing all the images.
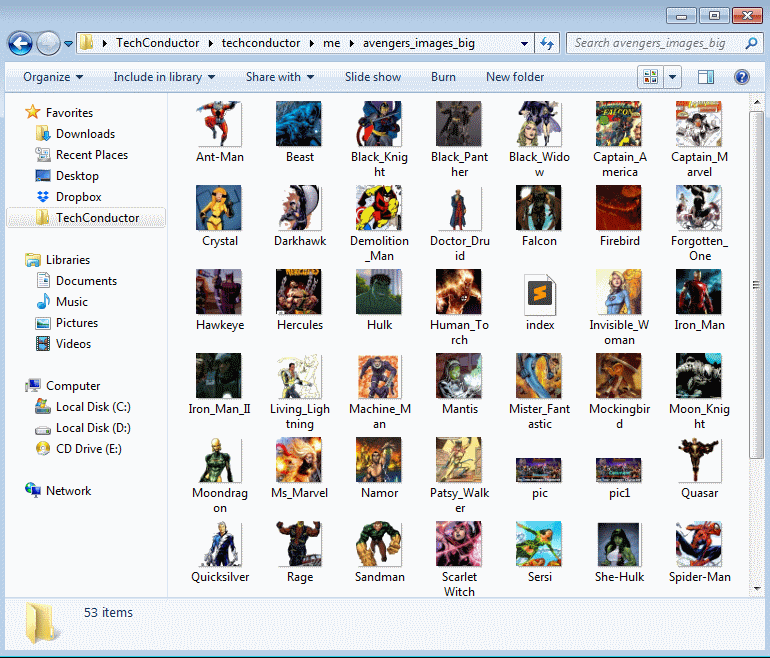
Thats all for now you may want to visit BeautifulSoup and Python websites for further reading and documentations. Also kudos to Raker.com ;-) Dont forget to Like and Subscribe below if you found it helpful.