Fetch json data about all the comic on XKCD.
- 23-06-2018
- python

Share:
Copy
XKCD is a webcomic of romance, sarcasm, math, and language. There are many interesting comics to browse which can easily chill your mood when you are frustrated or boured
If you want to extract all the images from xkcd comic using python and BeautifulSoup you can check out this article below.
How to download all XKCD comic.
If you don't want to use BeautifulSoup there is an excellent alternative provided by XKXD itself.
All the XKCD comic has an info.0.json file which has all the information related to the comic.
Each comic on XKCD has its own id which starts from 1 belonging to first comic, 615 belonging to 615th comic and so on.
To view 615th comic browse to https://xkcd.com/615/
Now as we can browse over all the comics its time to fetch the json data about each comic. Its also simple just use info.0.json at the end of each comic url.
https://xkcd.com/615/info.0.json
The above url will output the json data shown below of that specific comic.
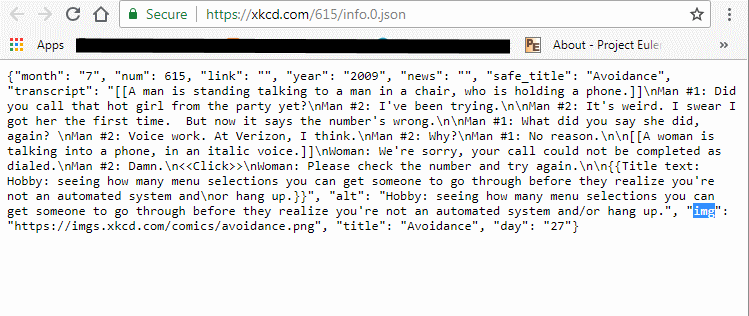
The above json data can be used to do many things such as, downloading comic images using the 'img' value from the json data, we can also make a catalog using the 'title' value, also we can make a better interface than the XKCD website to view or browse the comics using better degins and so on.
Here is a simple example to extract the image link or url from the json data and itterate over all the comic images provided in the for loop range.
from urllib.request import urlopen, urlretrieve import json for i in range(1, 50): #number of comics to download from 1 and upto. url = 'https://xkcd.com/'+str(i)+'/info.0.json' u = urlopen(url) page_html = u.read() u.close() json_data = json.loads(page_html) print(json_data['img'])
Result
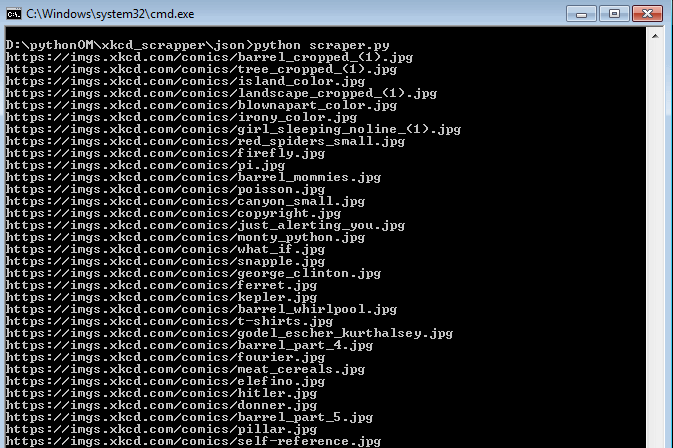
The above code can be used in place of the BeautifulSoup in this article on how to download all the comic images from XKCD.
Reference: xkcd.com